

| その1 | その2 | その3 | その4 | その5 | その6
前回のおさらい
【前回までのストーリー】
・国立国会図書館件名標目 タブ区切りテキストファイルをダウンロード
・エクセルで開けるようにする(場合によってはテキストファイルで分割)
・エクセルの関数を使って「同義語」を分割。
第3回は、上位語、下位語、関連語の分割について
ダウンロードして、エクセルで開けるようにしたデータは、同義語、上位語、下位語、関連語が、それぞれ複数あってもひとつのセルに入っている。ひとまずちゃんとしたデータベースを作成するには、それらを分割する必要があります。ひとつふたつなら手作業でコピー、カット&ペーストで作業できるのですが、これがひとつのセルに30個以上の件名(単語)が入っていたり、全体が数万レコードあったりする…となると、ひとつひとつ手作業で行うわけにはいきません。そこでこんな風に要領よく、楽をするための努力は惜しまない…ということでやってみました。なお、上位語、下位語、関連語は同様の処理なので、ここでは下位語の作業を中心に書いておきます。
下位語の分割




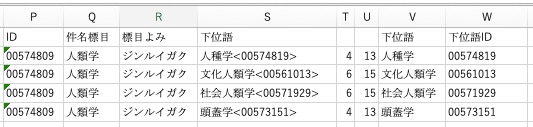
ID: 00574809 人類学の[下位語]には4つの件名がありますが、それがひとつのセルの中に入っているので、このままでは操作ができません。まずはこの項目を分割します。
小さくてわかりにくいので
まずは、
- E2: 区切り文字[;]の個数を数える =LEN(D2)-LEN(SUBSTITUTE(D2,”;”,””))
- F2: 最初の区切り文字の位置 =IF(ISERROR(FIND(“;”,D2,1)),””,FIND(“;”,D2,1))
- G2: 二番目の 〃 =IF(ISERROR(FIND(“;”,D2,F2+1)),””,FIND(“;”,D2,F2+1))
- H2: 三番目の 〃 =IF(ISERROR(FIND(“;”,D2,G2+1)),””,FIND(“;”,D2,G2+1))
- I2: 文字列全体の長さ(文字数) =LEN(D2)
これをもって
- K2: 最初の下位語 =MID(D2,1,F2-1)
- L2: 二番目の下位語 =MID(D2,F2+1,G2-F2-1)
- M2: 三番目の下位語 =MID(D2,G2+1,H2-G2-1)
- N2: 四番目の下位語 =MID(D2,H2+1,I2-H2)
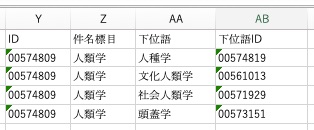
を抽出します。これをコピーし、形式を選択してペースト…その際は◎数値を選択肢、□行列を入れ替えるにチェックをする。そしてこんな風になります。
次に、下位語を 下位語と下位語IDに分割
- T2: 下位語のIDの区切り文字 [<]の位置 =IF(ISERROR(FIND(“<“,S2,1)),””,FIND(“<“,S2,1))
- U2: 下位語のIDの区切り文字[>]の位置 =IF(ISERROR(FIND(“>”,S2,1)),””,FIND(“>”,S2,1))
- V2: 下位語のみ =LEFT(S2,T2-1)
- W2: 下位語ID(数字のみ) =MID(S2,T2+1,U2-T2-1)
以上の操作で、件名と下位語のリレーションテーブルのベースができあがります。
同様の操作(関数)によって、上位語および関連語を分割し正規化を行います。

平日は山中湖村の森の中にある図書館 山中湖情報創造館に、週末は清里高原の廃校になった小学校を活用したコワーキングスペースもある 八ヶ岳コモンズにいます。「わたしをかなえる居場所づくり」をイメージしながら、テレワークに加えて動画撮影やネット副業などにもチャレンジできる図書館/コワーキングスペースづくりに取り組んでいます。


コメント