

| その1 | その2 | その3 | その4 | その5 | その6
【前回までのストーリー】
・国立国会図書館件名標目 タブ区切りテキストファイルをダウンロード
・エクセルで開けるようにする(場合によってはテキストファイルで分割)
・エクセルの関数を使って「同義語」を分割。
・エクセルの関数やコピペ(数値や行列を入れ替えるなども使いながら)によって、件名、同義語、上位語、下位語、関連語を分割。
・FileMaker Proにて件名データベースを作成、正規化した同義語もインポート(1:多のリレーション)上位語・下位語・関連語は[多:多]のリレーション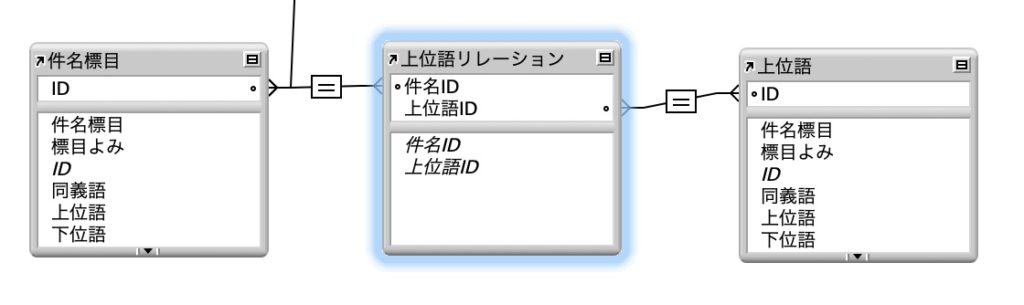

・エクセルの関数やコピペ(数値や行列を入れ替えるなども使いながら)によって、件名、同義語、上位語、下位語、関連語を分割。
・FileMaker Proにて件名データベースを作成、正規化した同義語もインポート(1:多のリレーション)上位語・下位語・関連語は[多:多]のリレーション
同義語においては件名標目ではない言葉が関連づけられていましたが、上位語・下位語・関連語は、どれも同じ「件名標目」の別の言葉が関連づけられています。この場合は[1:多]のリレーションではなく、[多:多]のリレーションを作る必要があります。その際には、新たに[多:多のリレーションテーブル]を作成し、その両側に「件名標目」のテーブルを関連づける必要があります。
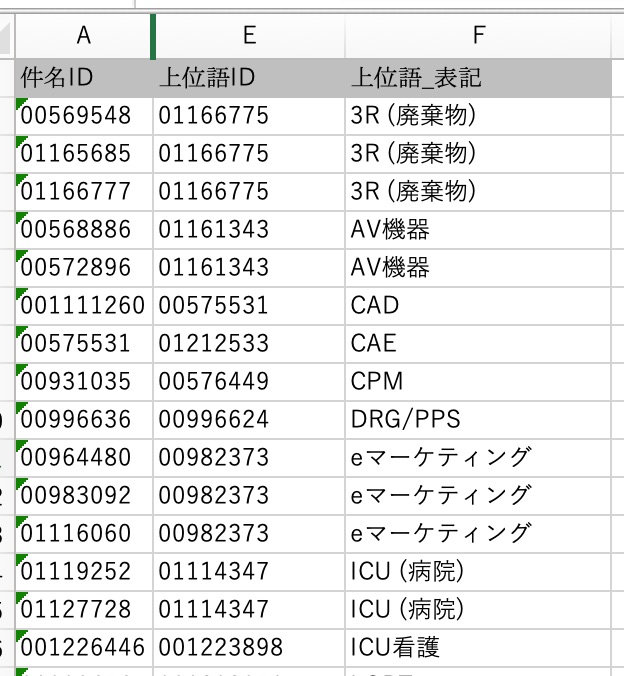
左側のテーブルは[件名標目]、右側のテーブルも同じ[件名標目]のテーブルですが、ここではわかりやすいように[上位語]と名前を変えています。間にあるテーブルが件名と上位語を関連づける[多:多のリレーションテーブル]になります。この「上位語リレーションテーブル」には、Excelで作成したこの表をインポートします。
このA列を件名IDに、E列を上位語IDにインポートします。
これで、件名標目と上位語の多:多リレーションができあがり。
同様に、下位語、関連語についても、同様のリレーションテーブルを作成して、Excelで整形したデータをインポートすることで、作成できます。
テーブルとフィールドとリレーションは、こんな感じになります。
ここまでで、国立国会図書館の件名表目標のデータベースが作成できます。

平日は山中湖村の森の中にある図書館 山中湖情報創造館に、週末は清里高原の廃校になった小学校を活用したコワーキングスペースもある 八ヶ岳コモンズにいます。「わたしをかなえる居場所づくり」をイメージしながら、テレワークに加えて動画撮影やネット副業などにもチャレンジできる図書館/コワーキングスペースづくりに取り組んでいます。


コメント