

| その1 | その2 | その3 | その4 | その5 | その6
前回のおさらい
1.国立国会図書館 件名表目標をダウンロード
http://id.ndl.go.jp/information/download/
・RDF/XML形式ダウンロード
・TAB区切りテキスト形式ダウンロード←こんかいはこちら。
2.TAB区切りテキストをExcelで読み込む
ファイルが大きいのでテキストエディタ等で分割して読み込むといいかも。
(丸山は一度FileMakerProで読み込んで、Excel形式で保存)
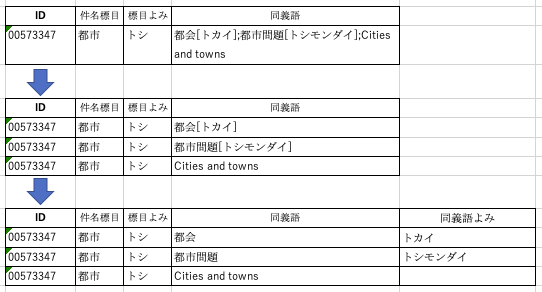
3.ひとつの件名に対して、同義語、上位語、下位語、関連語があるが、それぞれ一つのセルに複数の件名が入っているので、分割する。
ということで、分割のコツは、Excelの関数を上手に使うこと。
| D | E | F | G | H | I | J | K | |
| 2 | 都会[トカイ];都市問題[トシモンダイ];Cities and towns |
E2・区切り文字の数を数える関数 =LEN(D2)-LEN(SUBSTITUTE(D2,”;”,””))
F2・最初の 区切り文字[;]の位置 =IF(ISERROR(FIND(“;”,D2,1)),””,FIND(“;”,D2,1))
(一応エラー処理も)
G2・二番目の区切り文字[;]の位置 =IF(ISERROR(FIND(“;”,D2,F2+1)),””,FIND(“;”,D2,F2+1))
H2・文字列全体の長さ =LEN(D2)
I2・最初の文字列の抽出 =MID(D2,1,F2-1)
J2・二番目の文字列の抽出 =MID(D2,F2+1,G2-F2-1)
K2・三番目の文字列の抽出 =MID(D2,G2+1,H2-G2)
ひとまずこれで
| D | E | F | G | H | I | J | K | |
| 2 | 都会[トカイ];都市問題[トシモンダイ];Cities and towns | 2 | 8 | 21 | 37 | 都会[トカイ] | 都市問題[トシモンダイ] | Cities and towns |
あとは、IJK列をコピーして、ペーストする際に[形式を選択してペースト…]で、数値を選び、行列を入れ替えるで OK すれば、横に並んだ文字列が縦にならびます。あとは元の件名を下にコピーすればできあがり。
—
このままでは、I、Jの文字列にはまだヨミガナが入っているので、同じ要領で、今度は区切り文字が [ と] であることから文字の場所を計算し、抽出すればできあがり。

平日は山中湖村の森の中にある図書館 山中湖情報創造館に、週末は清里高原の廃校になった小学校を活用したコワーキングスペースもある 八ヶ岳コモンズにいます。「わたしをかなえる居場所づくり」をイメージしながら、テレワークに加えて動画撮影やネット副業などにもチャレンジできる図書館/コワーキングスペースづくりに取り組んでいます。


コメント