
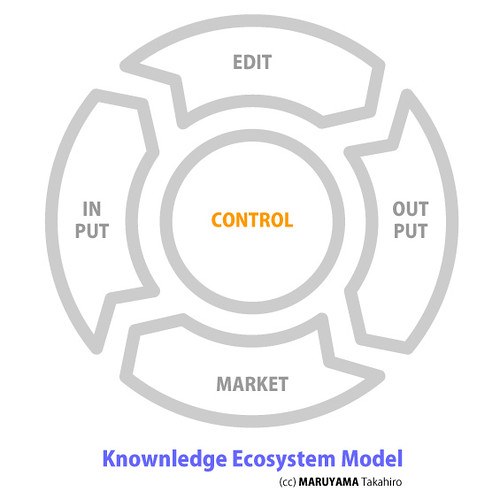
僕は「知のエコシステム Knownledge Ecosystem」を考える時に、ひとつの参考として「食べ物の流通」をモデルとしています。「食」を「知」と置き換えてみると、実にいろいろと判ってくる事があったりします。
INPUT:入力
「知の摂取」と言い換えると判りやすいかな。本を読む、映画を観る、音楽を聴く…人の話を聞く…などなど。様々な形で人は五感を通して「情報・知識・物語」を摂取してきました。そのパートをここではINPUTとします。
知のエコシステムにおけるINPUTの内容には、次のようなものがあると考えます(順不同)。
・入手する
・ストックする
・摂取する
・クリッピング/スクラップする
・ノートをとる
例えば…本屋さん(マーケットの一部:小売り)に行って、本を立ち読み(摂取)、購入(入手)し、家に持ち帰り本棚に(ストック)。気になる記事はコピーするか切り抜いて(クリッピング&スクラップ)したり、ノートを取ったり…。
料理に例えていえば、スーパーマーケットで食材を購入してきて、冷蔵庫(ストック)に入れたり、調理するために切り刻んだり(クリッピング&スクラップ)、下ごしらえをしたり…、自分で食べるために調理したり(ノート)などの行為と置き換えることもできる。
現在あるデジタル系インターネット系技術で考えると
・電子書籍端末(ハードウェア)やiPadのiBooks(アプリ)など、マーケットから購入して自分のセレクションとして[ストック]
・Evernoteのようなアプリ/サービスを使って、クリッピング&スクラップ
がすでに実現している。
これらが、次の…次の次の段階くらいに、[手続きコピペ]と[感謝の還元]を考慮したAPIのようなものに対応することで、「知のエコシステム」の循環の中に位置づけるられる可能性はある。
このINPUTでのポイントは
・クリッピング&スクラップしたコンテンツに対して、1)データそのもの に加えて、2)権利者情報や、3)二次利用ライセンス課金情報 を持った[手続きコピペ]に対応していることなんだ。
(このつづきは、また後日)
※「知のエコシステム」ができると、実は『公共図書館の役割』がとても重要な存在になります。[手続きコピペ]や[感謝の還元]をシステム化すると、すべてのメディア/コンテンツを購入しなければならない…ということはないのです。それよりもむしろ、できるだけ多くのコンテンツに触れ引用や参考にすることの方がメリットがある…という状況になります。このあたりは、循環を書き上げてから、再度記述したいと思います ※

平日は山中湖村の森の中にある図書館 山中湖情報創造館に、週末は清里高原の廃校になった小学校を活用したコワーキングスペースもある 八ヶ岳コモンズにいます。「わたしをかなえる居場所づくり」をイメージしながら、テレワークに加えて動画撮影やネット副業などにもチャレンジできる図書館/コワーキングスペースづくりに取り組んでいます。

コメント